If you have been following this series, you’ve learned how to install and configure minikube and get started with running SQL Server within Kubernetes. In the final part of this series, you will learn about how failover works, and how you can do an rolling upgrade of SQL Server.
How This Works
Kubernetes works kind of like Windows Failover Clustering does–in that, since we have defined our service, it runs a health check on our pod running SQL Server. There is also a notion of auto-healing–our service should match our deployment manifest which is called Desired State, which means if our pod (the unit of our containment) goes away, the Kubernetes control plane will bring back our pod and therefore database. In the event that a node were to go away, since our deployment is stored in the Kubernetes master, SQL Server will come back online. The timing on this failover is very similar to a SQL Server Failover Cluster restart–as crash recovery will need to be performed. Let’s see how this works. In this first shot, we have a working instance–with a database called demo.
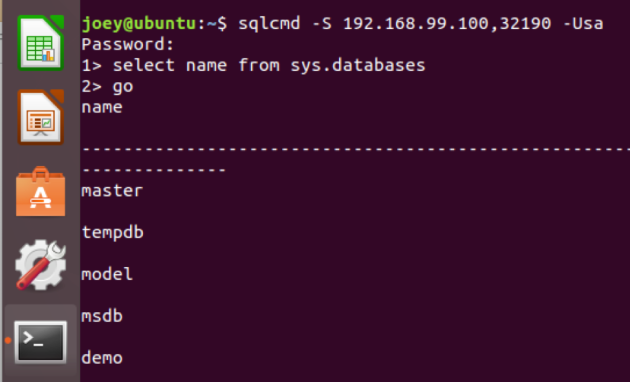
Next–I’m going to use the kubectl delete pod command, where we will remove our container.

As you can see in the kubectl get pod command, we have one container terminating and another creating. Next, I will run the kubectl logs command to get the log from our container–this is just the SQL Server error log, because it is written to stdout (that’s the standard output) in Linux.

Now, I can log back into my container and see my database.

Performing a Rolling Upgrade
One of the other cool things we can do is a rolling upgrade. In the manifest I supplied, when you build your container, you will always get the latest release of SQL Server. However, you can specify a specific CU–in this next example, I will change the image line in my manifest to pull down CU4 to image: microsoft/mssql-server-linux:2017-CU4. I’ve deployed that here, as you can see.

So, I’m simply going to change the image line in my manifest line, from CU4 to CU5 and then redeploy our manifest using the kubectl apply -f command. You will want to have deployed the version of SQL Server to test environment in your cluster to reduce your downtime–when you deploy the image is local to your cluster, which means the time to spin up your new container will be much lower.
You can see how that process worked in this screenshot.
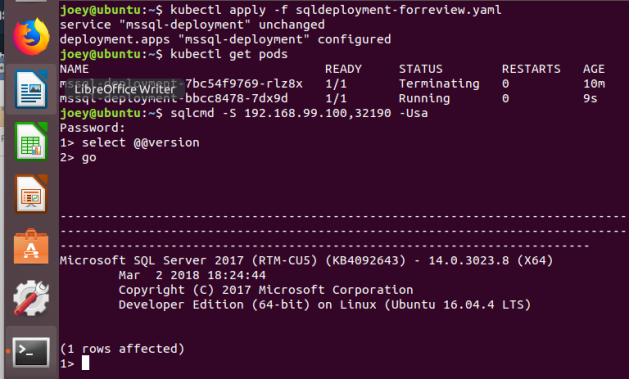
We’ve redeployed the template (which you can see by the change to deployment configured response from K8s) our pod terminated and restarted, and then SQL Server upgraded, and we were able to connect.
Summary
I hope you enjoyed this series of posts–I really feel like Kubernetes represents the future of infrastructure whether in the cloud or on-premises. Software defined infrastructure, and persisted storage make it easy to deploy and manage. When SQL Server gets some more features–the main ones I’m looking for are AD authentication and Always On Availability Groups, I think you will see far more widespread use of SQL Server on containers.